Introducción
Una vez que uno de los algoritmos de sintetización de Dedomena es entrenado, Nucleus provee un resumen en la versión Nucleus Edge y un reporte en las versiones edge y cloud. Para obtener el reporte usando la versión Nucleus Edge, el synthesizer debe ser subido a la plataforma.
Para calcular las métricas y scores, se toma una muestra de datos reales y sintéticos, logrando los resultados lo más rápido posible y evitando cuellos de botella.
Scores
Con el fin de simplificar y vislumbrar cuán seguros y valiosos son los datos, Dedomena provee tres scores:
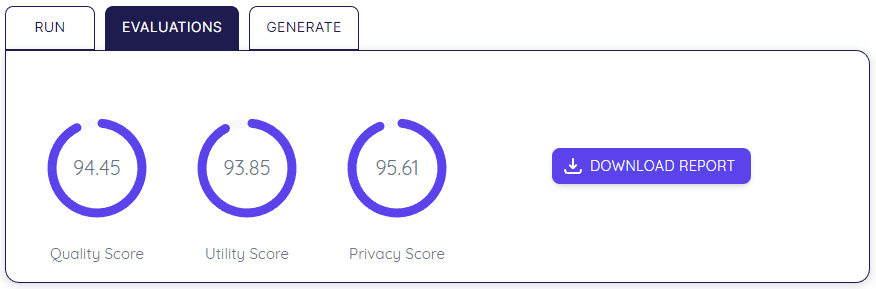
-
Privacy: cuán privados y seguros son los datos sintéticos.
-
Quality: cuán buenos son los datos sintéticos manteniendo el valor, patrones, estadísticas, relaciones, etc.
-
Utility: robustez de los datos sintéticos para reemplazar los datos reales en tareas de Machine Learning.
Métricas
Dedomena provee métricas para cada dimensión de los datos sintéticos que analiza y mide: privacy, quality y utility.

Privacy
-
Distance to the closest record (DCR): puede interpretarse como la "menor" distancia entre cada elemento de los datos reales y los datos sintéticos. La métrica toma valores no negativos, donde 0 representa el peor resultado posible.
-
Exact Match Score (EMS): porcentaje de filas compartidas entre los datos sintéticos y los reales. La métrica toma valores en [0, 1], donde 0 representa el mejor resultado.
-
Nearest Neighbour Distance Ratio (NNDR): esta métrica se define como la razón entre la menor distancia entre un elemento del dataset real y la segunda menor distancia. La métrica toma valores en [0, 1], siendo 1 el valor óptimo.
-
Attribute Inference Attack (AIA): existen diferentes tipos de ataques de inferencia. En este caso, la métrica mide si es posible distinguir entre datos reales y sintéticos, haciendo posible que un atacante extraiga información de los datos reales a través de los sintéticos. La métrica toma valores en [0, 1], siendo 1 el valor óptimo.
Quality
-
Mean Correlation Score (MCS): se basa en el cálculo de la diferencia absoluta media entre las correlaciones de las variables tanto en los datos reales como en los sintéticos. Esta métrica típicamente fluctúa entre 0 y 1, pero en algunos casos puede superar 1. En tales casos, se puede usar el valor de 1 como valor de referencia. Aquí, el valor de 0 representa el óptimo.
-
Cramér's V MSE Score (CVMS): la métrica se calcula como el MSE del Cramér's V (mide la asociación entre dos variables categóricas) tanto para los datos reales como para los sintéticos. La métrica fluctúa entre 0 y 1, donde 0 representa el valor óptimo.
-
MSE Correlation Score (MSCS): se basa en calcular el MSE de las correlaciones entre las variables para los datos reales y los sintéticos. Dado que los valores de correlación van de 0 a 1, la métrica también fluctúa entre estos valores, donde 0 representa el valor óptimo.
-
Jensen-Shannon divergence score (JSDC): este score se basa en la divergencia de Jensen-Shannon. La divergencia de Jensen-Shannon se calcula entre los datos reales y los sintéticos para variables univariadas y para combinaciones de 2 a 2 y de 3 a 3 variables en cada caso. El propósito de considerar las combinaciones de variables de a 2 y de a 3 es detectar posibles relaciones subyacentes entre variables que pueden no ser evidentes al analizarlas individualmente. El score fluctúa entre 0 y 1, donde 0 representa el valor óptimo.
-
Linear correlations: relaciones lineales entre dos variables.
-
Distributions plots: gráficos de las distribuciones, continuas, fechas y categóricas o discretas.
Utility
Estas métricas pueden incluir la accuracy de clasificación y la capacidad de los datos generados para ser usados en tareas de ML. Una métrica de utility comúnmente usada es TSTR, que significa Train on Synthetic, Test on Real. Esta métrica implica entrenar un modelo con datos sintéticos generados por el synthesizer y luego probar el modelo con datos reales para evaluar su desempeño. Si no se provee un target, se usará una de las variables como target.
-
TRTR: Train on Real, Test on Real
-
TRTS: Train on Real, Test on Synthetic
-
TSTR: Train on Synthetic, Test on Real
-
TSTS: Train on Synthetic, Test on Synthetic