Creación de datos sintéticos a partir de un CSV
Dedomena ayuda a generar observaciones sintéticas a partir de datos reales en cuestión de minutos, horas o días. Desde data scientists que buscan probar un modelo de machine learning hasta analistas de negocio que quieren crear reportes sobre datos ficticios, el software de DEDOMENA.AI es la solución perfecta gracias a su flexibilidad, facilidad de uso y robustez para tareas donde se necesitan datos sintéticos para impulsar resultados de negocio, cumplir con regulaciones o proteger la privacidad de los datos. Managers, estudiantes, ingenieros, data scientists y otros perfiles pueden usar fácilmente la tecnología de generación de datos sintéticos de NUCLEUS con poco entrenamiento y evaluación.
A continuación, se describen las características clave del software de Dedomena para generar datos sintéticos y los pasos necesarios para comenzar:
1. Ir a la pestaña Nucleus
Si no hay una suscripción activa, aparecerá la vista de bienvenida, donde se puede activar el trial gratuito o una suscripción a uno de los planes de Nucleus.
Una vez que el trial gratuito o la suscripción esté activa, la vista para gestionar synthesizers o crear o subir un synthesizer reemplazará la vista de bienvenida.
El siguiente paso es subir un CSV a la plataforma mediante el botón ADD DATASET en el espacio MY DATA dentro de la pestaña AXON.
2. Subir un CSV mediante AXON
En AXON, en el espacio MY DATA, al hacer clic en el botón ADD DATASET se mostrarán las opciones para iniciar el proceso de carga del CSV. El espacio MY DATA es donde todos los datasets del usuario estarán disponibles de forma privada independientemente de la fuente, ya sea que el usuario los haya subido, conectado o adquirido.

Para este tutorial selecciona la primera opción: Upload a CSV file to synthesize.

Solo se necesitan 4 pasos para tener un dataset subido y disponible en la plataforma. Para este ejemplo se usó este dataset disponible públicamente: Kaggle - Stroke Prediction Dataset.
Paso 1: Se busca y selecciona el CSV
A continuación se definen el nombre y la descripción del dataset que se va a subir.

Después, hay una vista previa disponible y es posible cambiar el nombre de cada variable marcando la casilla This table does not contain a header.

Paso 2: Definir las propiedades de las columnas.
El software detecta automáticamente el tipo de dato de cada variable, pero se recomienda validar y cambiar el tipo según las características de los datos y el conocimiento del feature space que solo el usuario maneja.
En este punto el usuario puede seleccionar qué variables son el target, primary key o sensitive con su tipo, si corresponde.

Se puede subir más de un dataset, haciendo posible en este paso definir las relaciones entre las tablas/datasets mediante la foreign key.
Paso 3: Relaciones entre tablas.
Si se subió más de un dataset, en este paso el usuario puede verificar y validar las relaciones entre las tablas/datasets.

Paso 4: Metadata del dataset.
Finalmente, se solicita cierta metadata sobre el dataset para hacer posible un filtrado y búsqueda avanzada.

3. Crear el synthesizer para generar datos sintéticos
Si los datos se subieron correctamente, una vez que hagas clic en CREATE SYNTHESIZER:

Aparecerá el dataset para ser seleccionado. Se muestra información general como el número de filas y columnas o las dimensiones de la metadata.

Desde esta vista es posible ejecutar una corrida de sintetización usando la capacidad de cómputo de la nube de Dedomena, que corre sobre GPUs de alta gama y tiene algunas restricciones de tiempo (24 horas de ejecución máxima). Para ejecutar corridas más costosas computacionalmente o que lleven más tiempo, se provee un componente on-premise: NUCLEUS EDGE.
Paso 1: Seleccionar el dataset
Para continuar, marca el dataset correspondiente en la columna include y haz clic en Next.
Nota: el dataset necesita tener al menos 1000 filas para ser válido para sintetizar. Dependiendo del plan también hay un límite respecto al número máximo de filas.
Paso 2: Seleccionar columnas
Dependiendo del plan, se permite un número máximo de columnas para la sintetización. En este ejemplo el número era 10. Usando las flechas se pueden incluir/excluir columnas fácilmente de la configuración específica de la corrida.

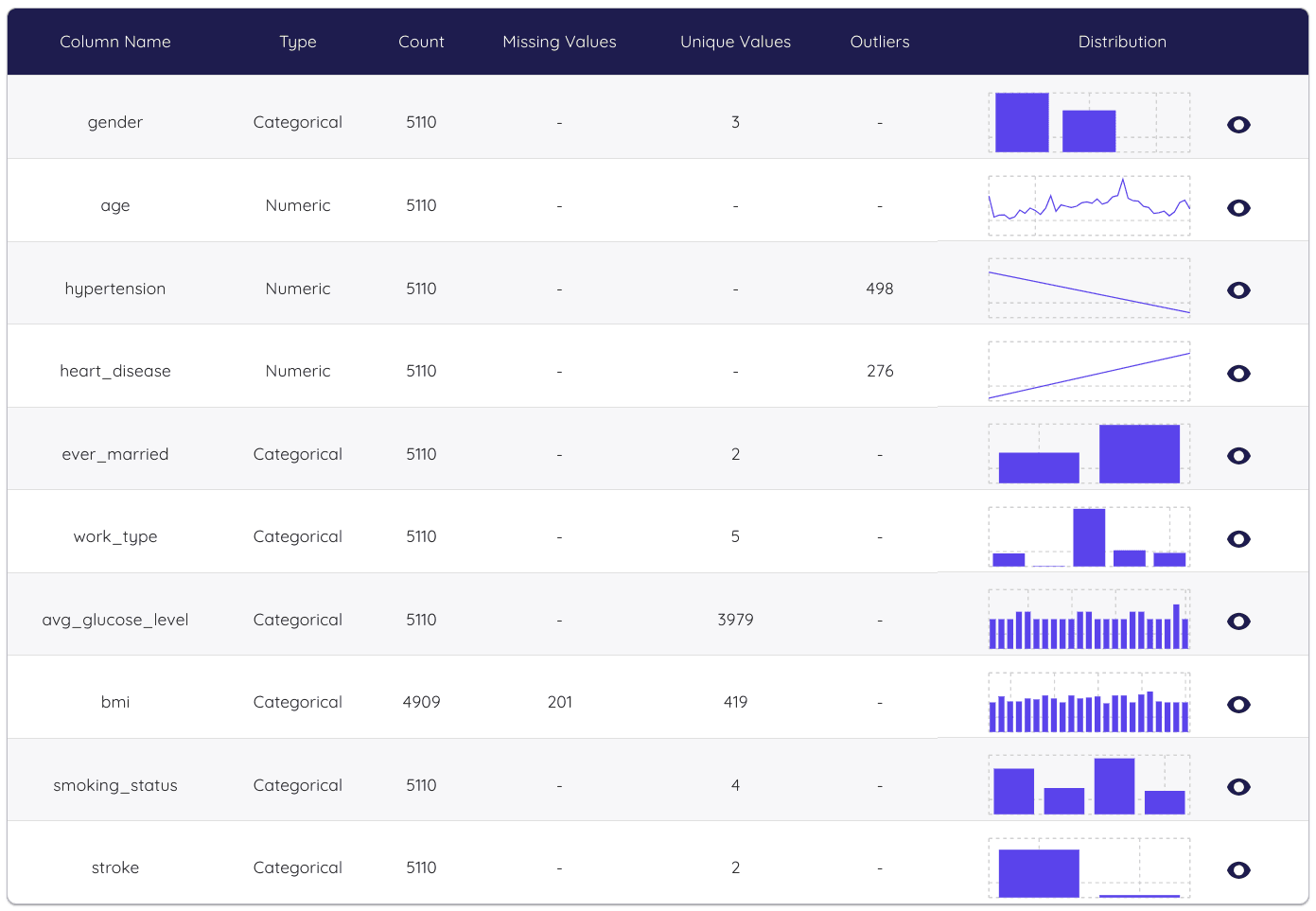
Paso 3: Data Profiling
Antes de entrenar el algoritmo de sintetización, Dedomena provee una sección de data profiling donde los usuarios pueden revisar el dataset a sintetizar y obtener información como el número de valores faltantes o únicos por columna, gráficos de distribución y estadísticas como mínimo, promedio o máximo.
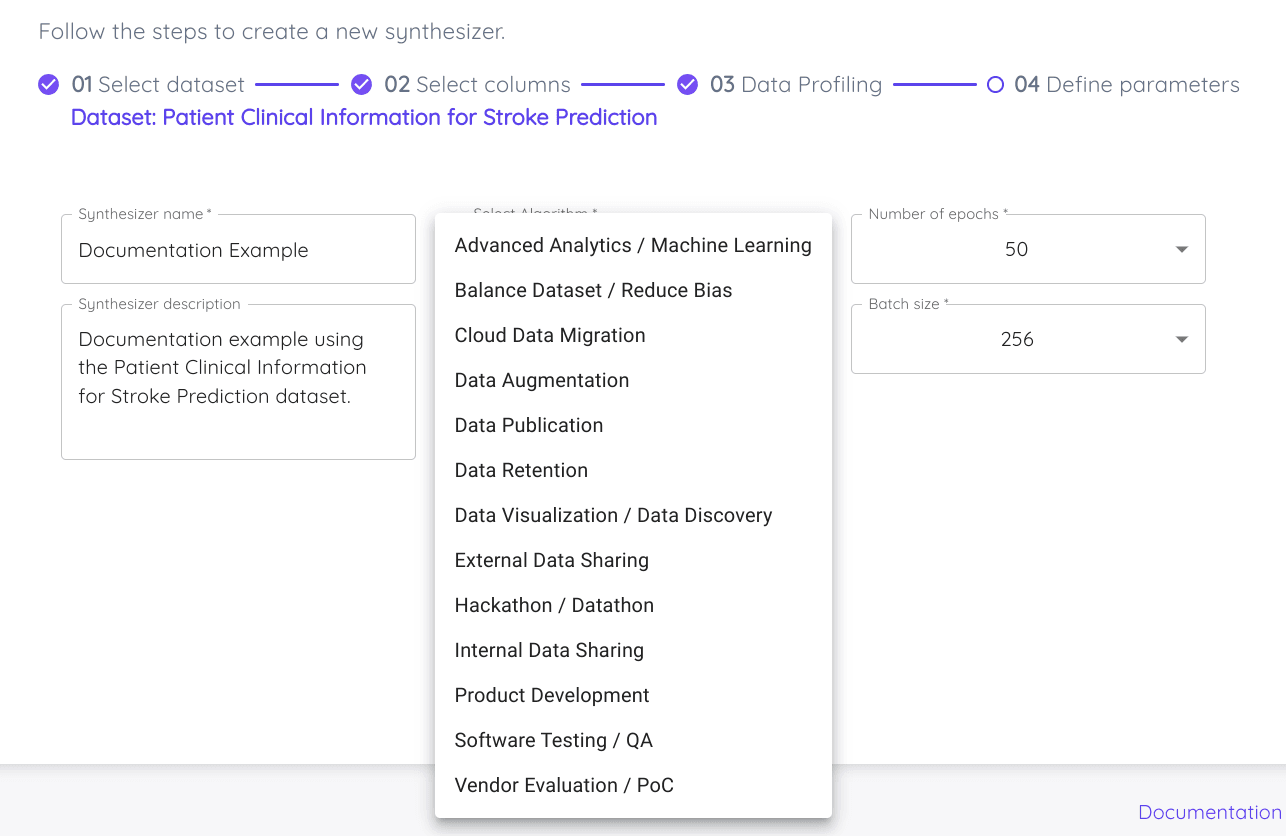
Paso 4: Parámetros de la corrida
El último paso es definir los parámetros de la corrida para crear el synthesizer, incluyendo la siguiente información:
-
Nombre del synthesizer.
-
Descripción del synthesizer.
-
Algoritmo a entrenar con los datos seleccionados.
-
Caso de uso que coincida con el propósito o aplicación del synthesizer a crear.
-
Número de epochs. Dada la complejidad de los datos, algunos datasets requerirán más epochs para aprender correctamente la información contenida en las variables.
-
Batch size.
4. Synthesizers de NUCLEUS
Si la corrida se lanzó correctamente, aparecerá la siguiente vista, mostrando un botón para ir a la pestaña Synthesizers en NUCLEUS.

Una vez en Synthesizers, se puede consultar el estado, los logs y el progreso de la corrida mientras se crea el synthesizer.

Mediante el botón Refresh la información se puede actualizar. La corrida se puede cancelar haciendo clic en el ícono de cruz.

Los logs permiten trackear el proceso de sintetización paso a paso.

Desde esta vista es posible acceder a cada synthesizer que ha sido:
-
Subido (entrenado localmente on-premise) o
-
Creado directamente en la plataforma (cloud)
Para obtener la información del synthesizer completado (o fallido): logs, métricas de evaluación de los datos sintéticos, pestaña de generación de datos sintéticos, etc.

Paso 1: Generar datos sintéticos
Para acceder a la información del synthesizer haz clic en el ícono Access Synthesizer (el del documento con la flecha) una vez que la corrida haya finalizado. Hay 3 pestañas:
-
Run: información general como el tiempo de entrenamiento, algoritmo de sintetización entrenado, número de epochs, etc.
-
Evaluations: los scores de Dedomena de un vistazo (Quality, Utility, Privacy) y un botón para descargar el reporte que analiza y compara extensivamente los datos reales vs sintéticos para determinar cuán buenos y seguros son los datos sintéticos.
-
Generate: generar y descargar los datos sintéticos.

A continuación ve a la pestaña Generate y selecciona el número de filas sintéticas a generar. Una vez que el proceso finalice, selecciona el formato del archivo de datos sintéticos y descarga el dataset sintético usando el botón Download a la derecha.

¡Felicitaciones! Un proceso end-to-end de sintetización y generación de datos se ha completado en pocos pasos, obteniendo datos sintéticos de clase mundial.