Unlocking Insights Safely: Privacy-Preserving Synthetic Data
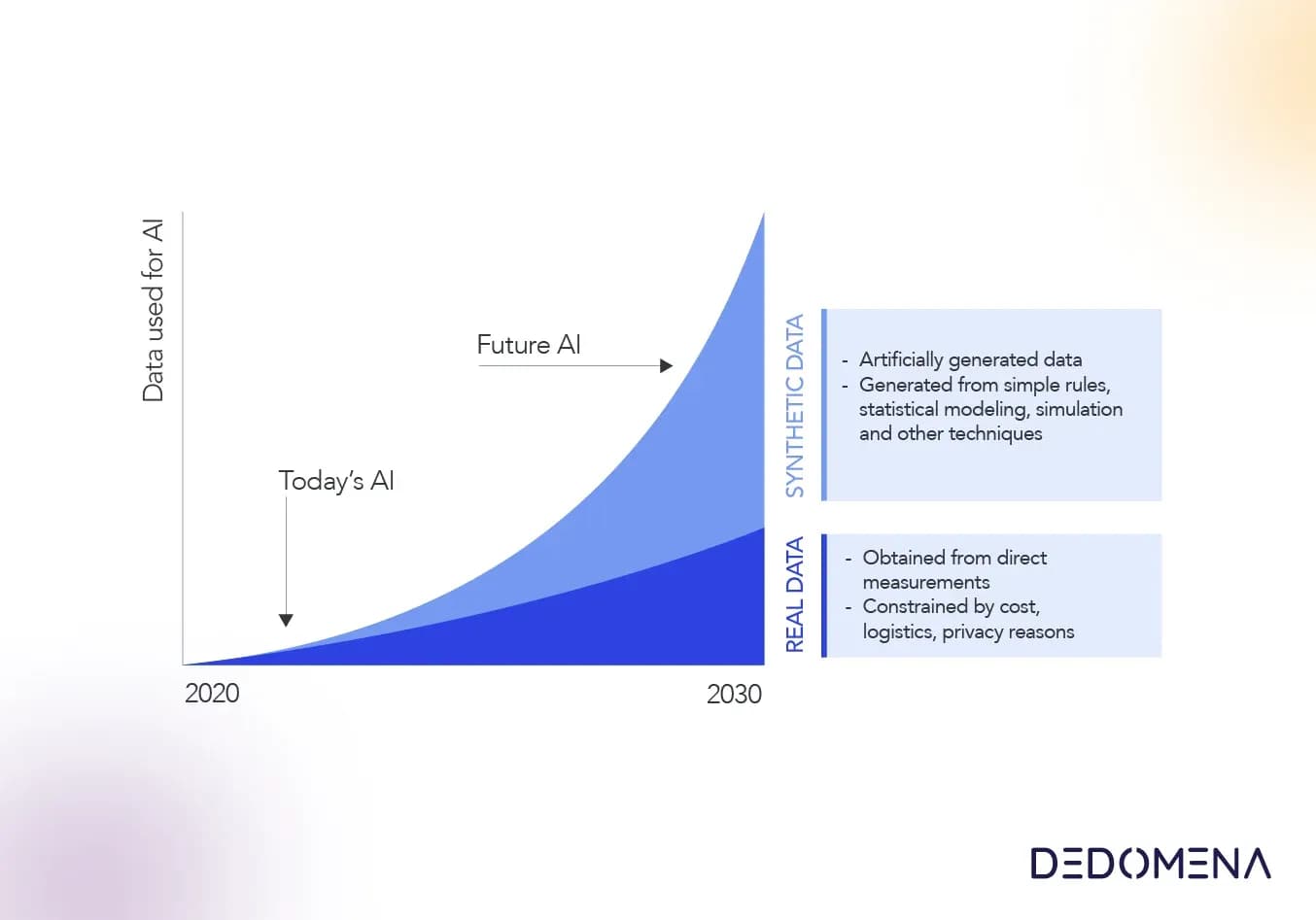
According to Gartner's predictions, synthetic data will be the dominant force in AI models by 2030. One key reason driving this shift is the increasing emphasis on privacy. As the fields of data science and artificial intelligence continually evolve, it becomes increasingly important to prioritize privacy while harnessing the power of data.
In a landscape that is often highly regulated, processing data can be complex, time-consuming, and fraught with security risks. One of the most pressing issues related to real data is the ethical and legal challenges surrounding privacy and consent. Synthetic data solutions are emerging as a viable remedy to these concerns. By generating synthetic data, the risk of exposing sensitive personal information—which can lead to privacy breaches and legal complications—can be effectively mitigated.
What is Data Privacy and Why is it so important?
Data privacy revolves around safeguarding personal data from unauthorized access, ensuring secure storage, securing informed consent, and complying with relevant laws. Personal data encompasses a wide range of information, including names, email addresses, Social Security numbers, financial account details, medical records, and biometric data.
Effective data protection is critical because it:
- Preserves individual privacy.
- Prevents data misuse.
- Ensures regulatory compliance (GDPR, CCPA).
- Fosters customer trust.
- Contributes to cybersecurity mitigation by reducing vulnerability to threats.
One approach that has gained momentum is privacy-preserving synthetic data. This concept involves generating artificial data that maintains essential statistical characteristics and patterns from an original dataset while safeguarding individual privacy. Organizations can create new datasets suitable for analysis without revealing sensitive information about the real individuals involved.
Benefits of privacy-preserving synthetic data
Privacy-preserving synthetic data offers numerous advantages:
- Embedded Privacy: It integrates protection directly into the data handling process.
- Efficiency and Flexibility: Enhances speed in data access and processing without compliance bottlenecks.
- Safe Collaboration: Promotes secure data sharing between departments or with external partners for research and development.
- Risk Mitigation: Allows organizations to thrive in a data-centric environment while minimizing the impact of potential data breaches.
In a landscape where data protection laws are strengthening, privacy-preserving synthetic data serves as a powerful tool for organizations to fortify their sensitive data. This approach represents a pivotal step towards achieving both privacy and progress in the realm of AI and data science. It holds the promise of revolutionizing data handling, creating a future where privacy and data-driven insights coexist harmoniously.


