
Synthetic Data Generation
Generate synthetic data from real datasets to securely share, analyze, develop solutions, and power AI projects while preserving privacy and maintaining data value.
Synthetic data for organizations that turn
data into a competitive advantage
Dedomena.AI's synthetic data generation technology replicates the statistical properties, relationships, and behavior of original data without including identifiable information. Create secure, consistent, and high-utility datasets for analytics, development, testing, collaboration, and artificial intelligence.
Sign up for freeHigh-Quality Data
Generate synthetic data that preserves the characteristics, complex patterns, and predictive power of the original data while maintaining its full utility.
- Preserves statistical properties, probability distributions, and linear, non-linear, bivariate, and trivariate relationships
- Maintains missing value patterns, outliers, target-to-feature relationships, recurring observations, temporal patterns, and more
- Generates all types of data, including numerical, categorical, dates, geolocation, IDs, and text
- Access four algorithms, including the market's most advanced model for banking data
- Learns from multiple tables or files simultaneously while preserving referential integrity
How It Works
Dedomena simplifies synthetic data generation so you can create secure, high-utility datasets in just a few steps.
Select Your Data
Choose the datasets you want to synthesize using the platform, API, or EDGE, and integrate the process seamlessly into your existing workflows.
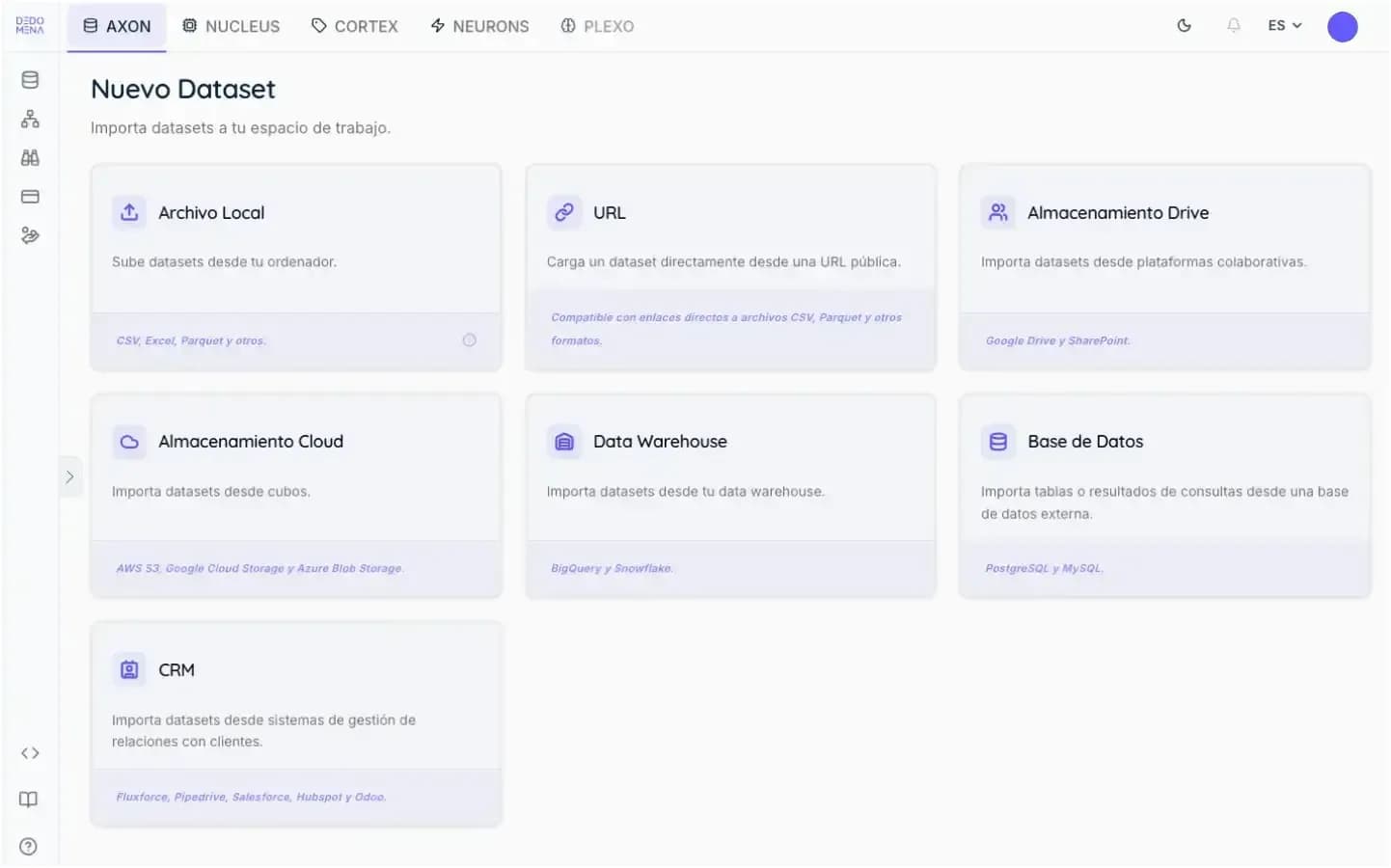
Configure the Training
Set the synthesizer training parameters, select the relevant columns for tabular data, choose the most suitable algorithm, and adjust the learning settings to match your dataset.
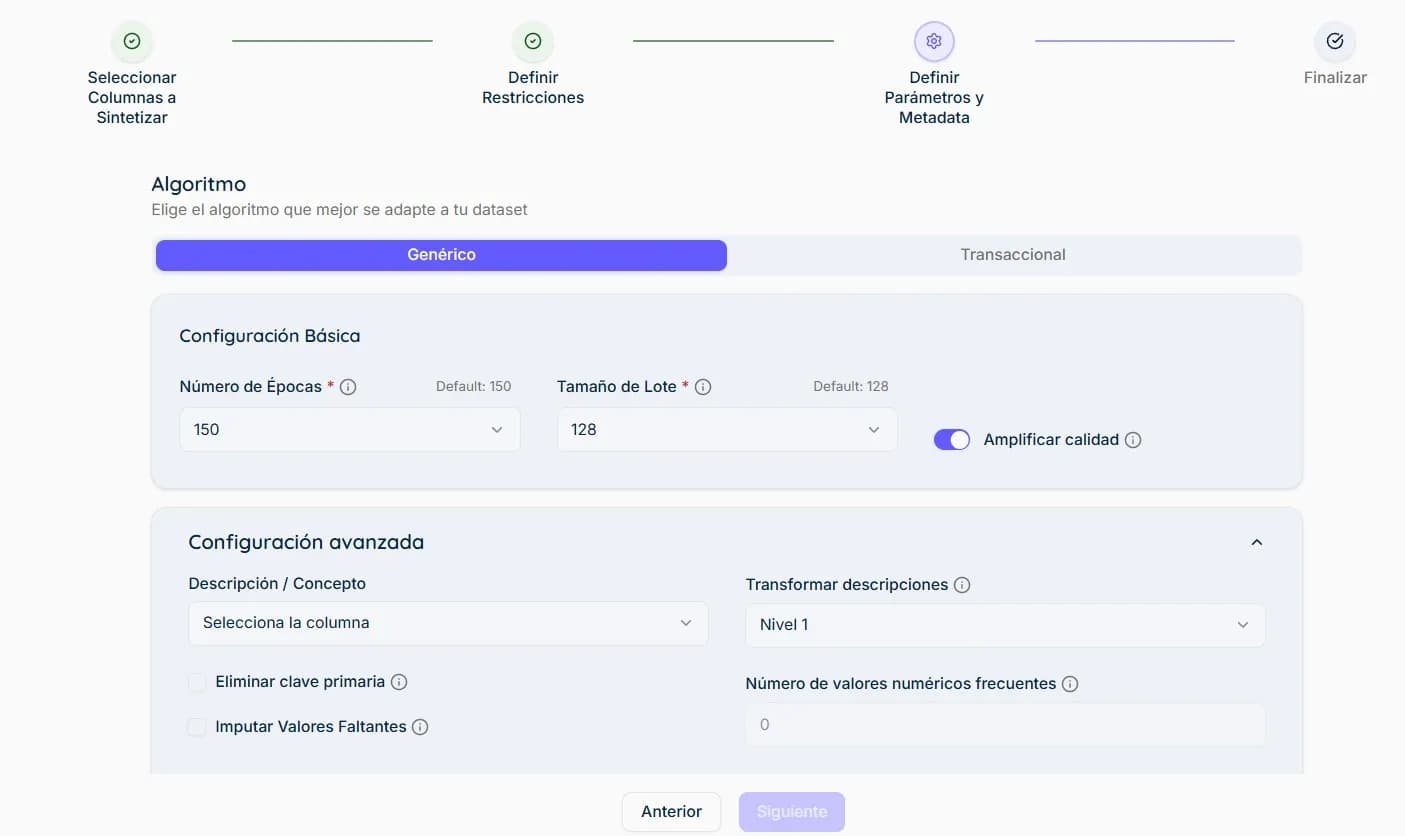
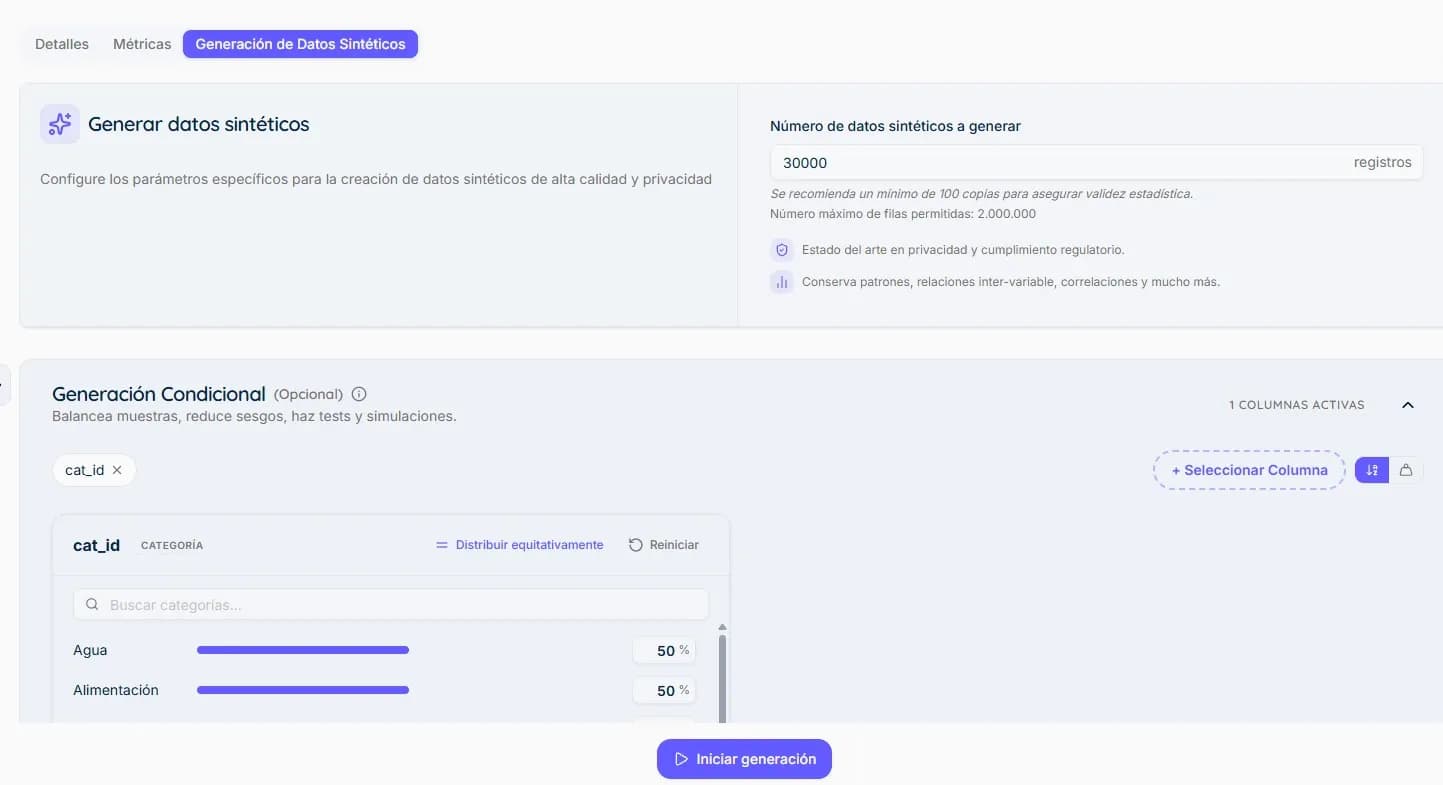
Generate Synthetic Data
Once training is complete, the synthesizer creates new synthetic records that preserve the structure, relationships, and statistical distributions of the original data while maintaining high quality, privacy, and utility.
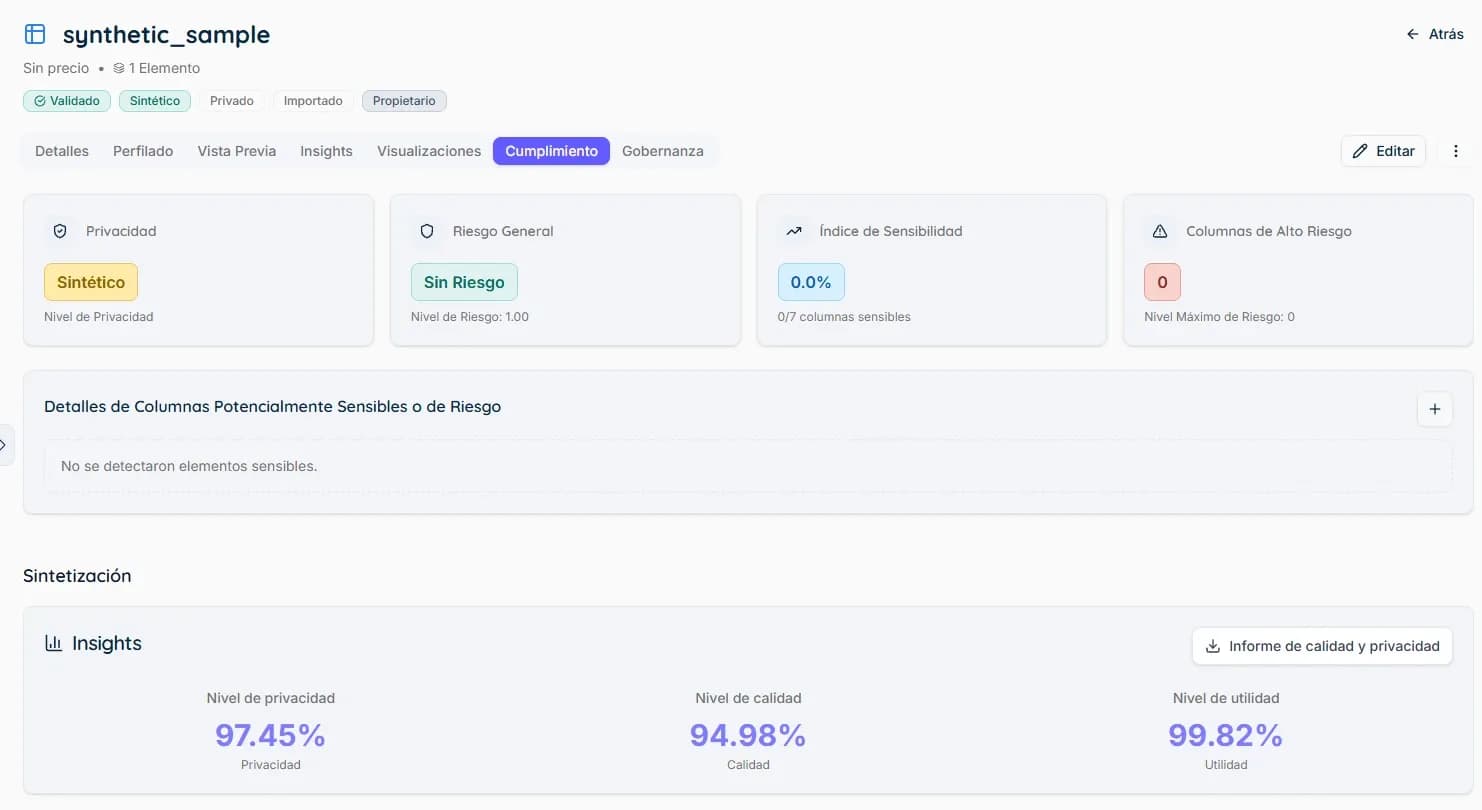
Use It with Confidence
When the process is complete, download the generated data or store it within your environment for secure use from your Workspace. Every generation includes a quality report that evaluates the utility and privacy level of the synthetic data before it is used for development, analytics, or data sharing.
Benefits
Turn sensitive data into a secure asset to accelerate projects, collaborate with third parties, and unlock more value from your information.
Regulatory Compliance
Reduce exposure to personal data by 90–95% in analytics and development environments, simplifying audits, data sharing, and compliance with GDPR and other privacy regulations without limiting access to data value.
Safer Analytics
Preserve over 90% of the statistical properties and predictive power of the original data, enabling advanced analytics, segmentation, and model development using fully anonymized information.
Data Sharing
Reduce the time required to enable data-sharing initiatives between departments, suppliers, and partners from weeks to days by removing many of the barriers associated with sensitive data access.
Higher-Quality AI
Expand and balance training datasets to reduce bias and improve the representativeness of data used to train AI models.
Development & Testing
Reduce data provisioning time by up to 80%, providing realistic datasets instantly for testing, QA, demonstrations, and functional validation.
Greater Agility
Generate millions of synthetic records on demand to accelerate new use cases, significantly reducing data preparation time while increasing experimentation and innovation.
10 Synthetic Data Trends to watch in 2025
Explore how synthetic data is reshaping industries, empowering innovation, and driving the future of AI.

Use Cases
Generate synthetic data to unlock the value of your data without compromising privacy.

Development & Testing
Use realistic data for functional testing, QA, integration, and software development without exposing sensitive information.

Analytics & Business Intelligence
Share data with business teams to build reports, dashboards, and advanced analytics while preserving privacy.

AI Training
Train, validate, and evaluate AI models using synthetic data. Balance minority classes and improve predictive model performance without compromising privacy.

Data Sharing
Enable secure data exchange between departments, customers, suppliers, and external partners.

Research & Innovation
Accelerate research projects, proof of concepts, and validation initiatives using secure and representative datasets.

Migration & Modernization
Migrate applications, consolidate systems, and transfer data across platforms while minimizing exposure to sensitive information.

2025: The year Synthetic Data becomes essential
Synthetic data is creating a global marketplace of possibilities, enabling innovation and collaboration like never before.

Unlocking Value: How Synthetic Data Transforms Data Assets
Discover how synthetic data can transform your data assets into new revenue streams while maintaining privacy compliance.

10 Use Cases for Privacy-Preserving Synthetic Data
Explore ten powerful use cases where synthetic data enables innovation while preserving privacy.

What is the ROI of Synthetic Data?
Understanding the return on investment when implementing synthetic data solutions in your organization.

What is Synthetic Data?
A comprehensive introduction to synthetic data: what it is, how it works, and why it matters.

Benefits of Synthetic Data
The key benefits of adopting synthetic data in your organization's data strategy.